
李宏毅机器学习笔记P54——transformer
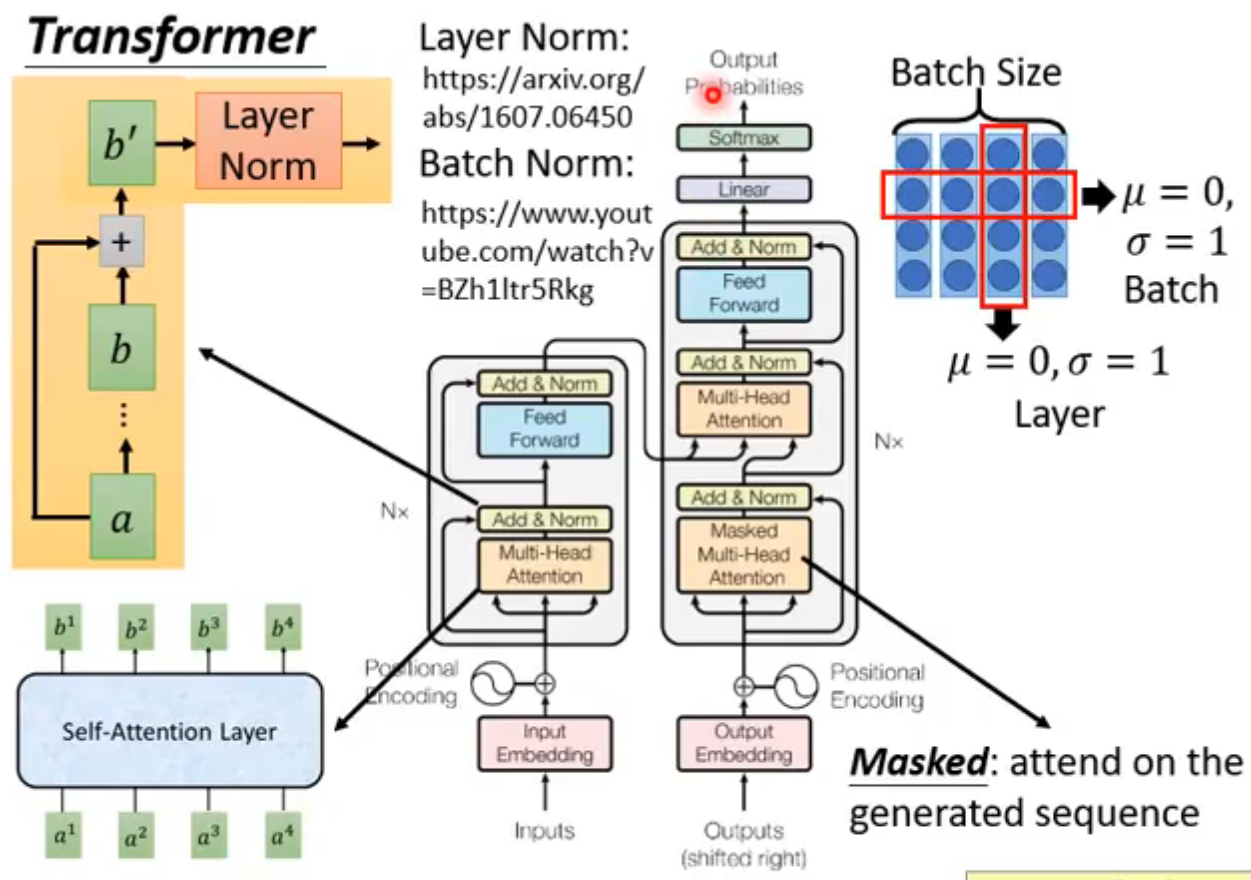
Transfomer
Seq2seq model with “Self-attention”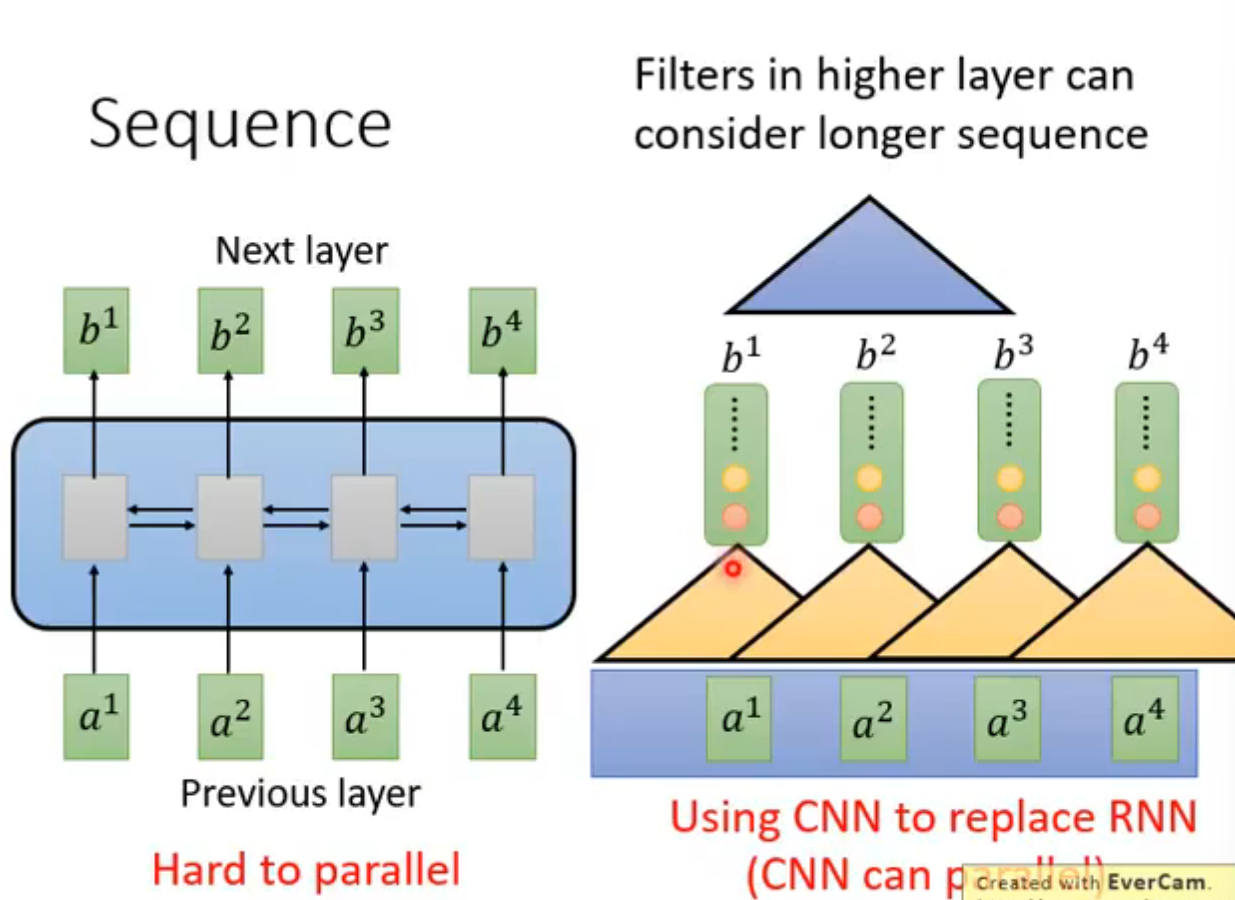
RNN缺点:读了a1才能读a2,无法并行
CNN替代RNN:多叠几层就能覆盖全部的输入,缺点就是需要的层数更多
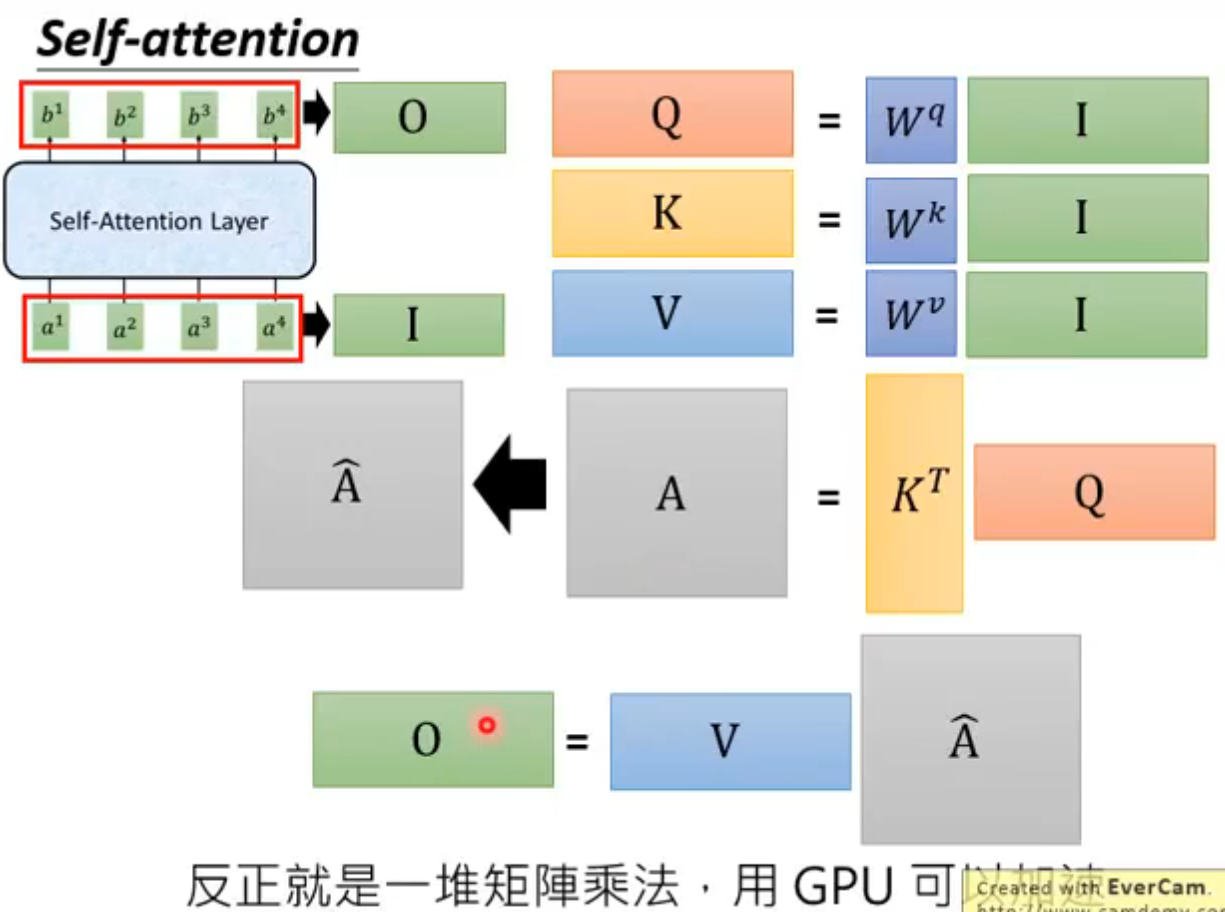
Self-Attention
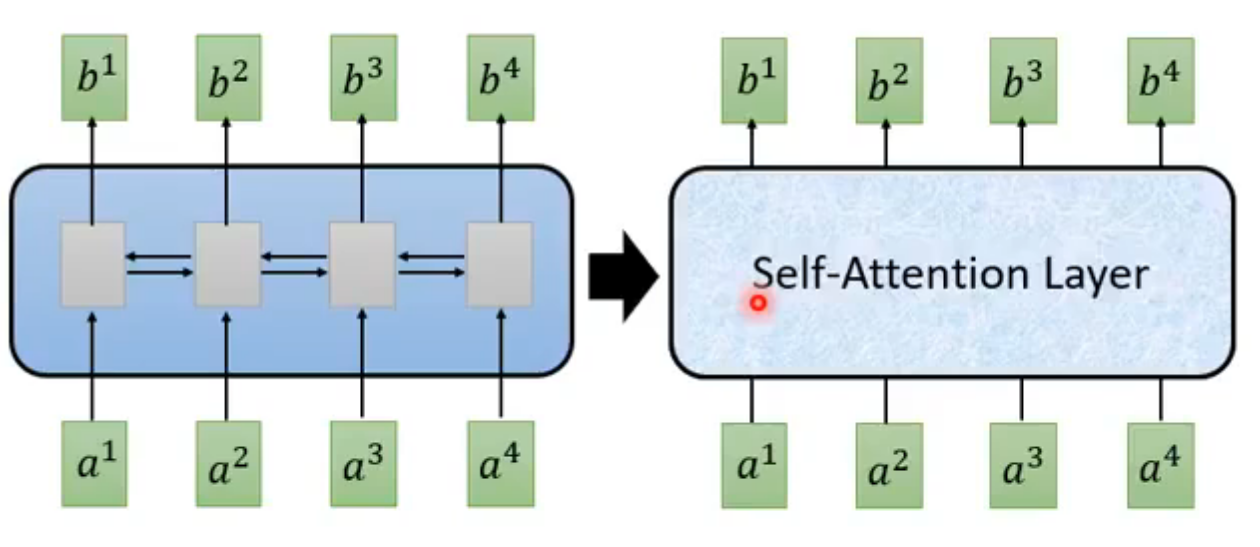
Self-Attention Layer,输入是一个Sequence,而且输出是同时输出的,可以并行
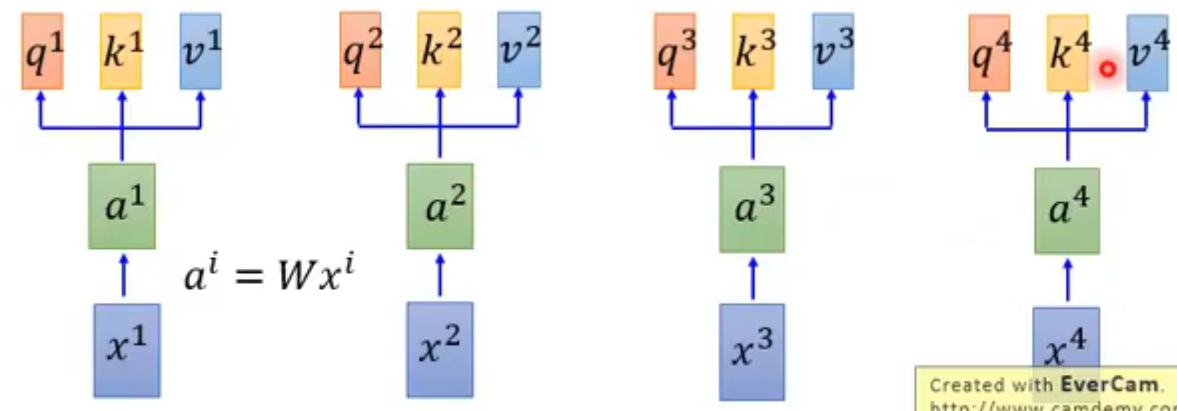

步骤
q对每一个k做Attention
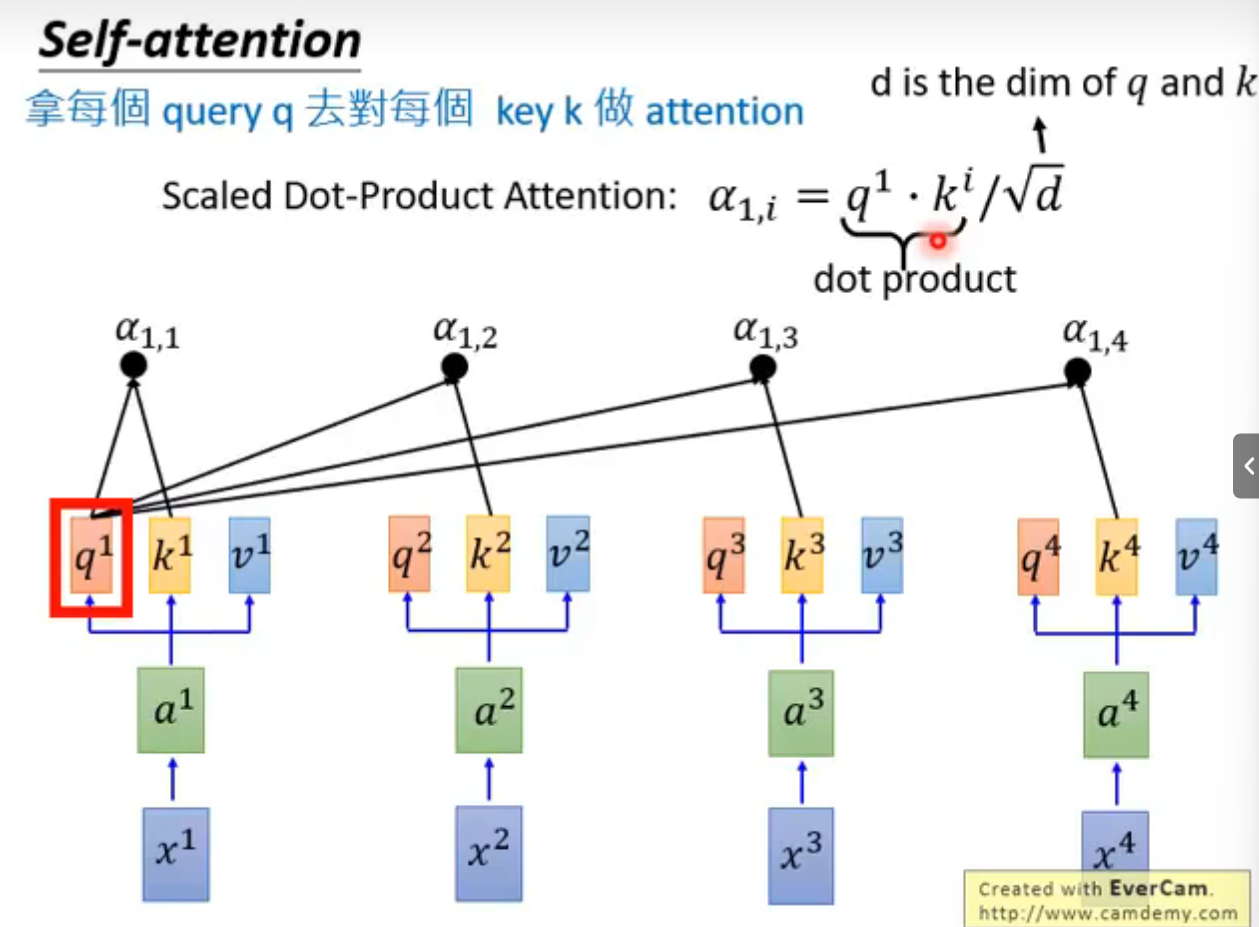
softmax
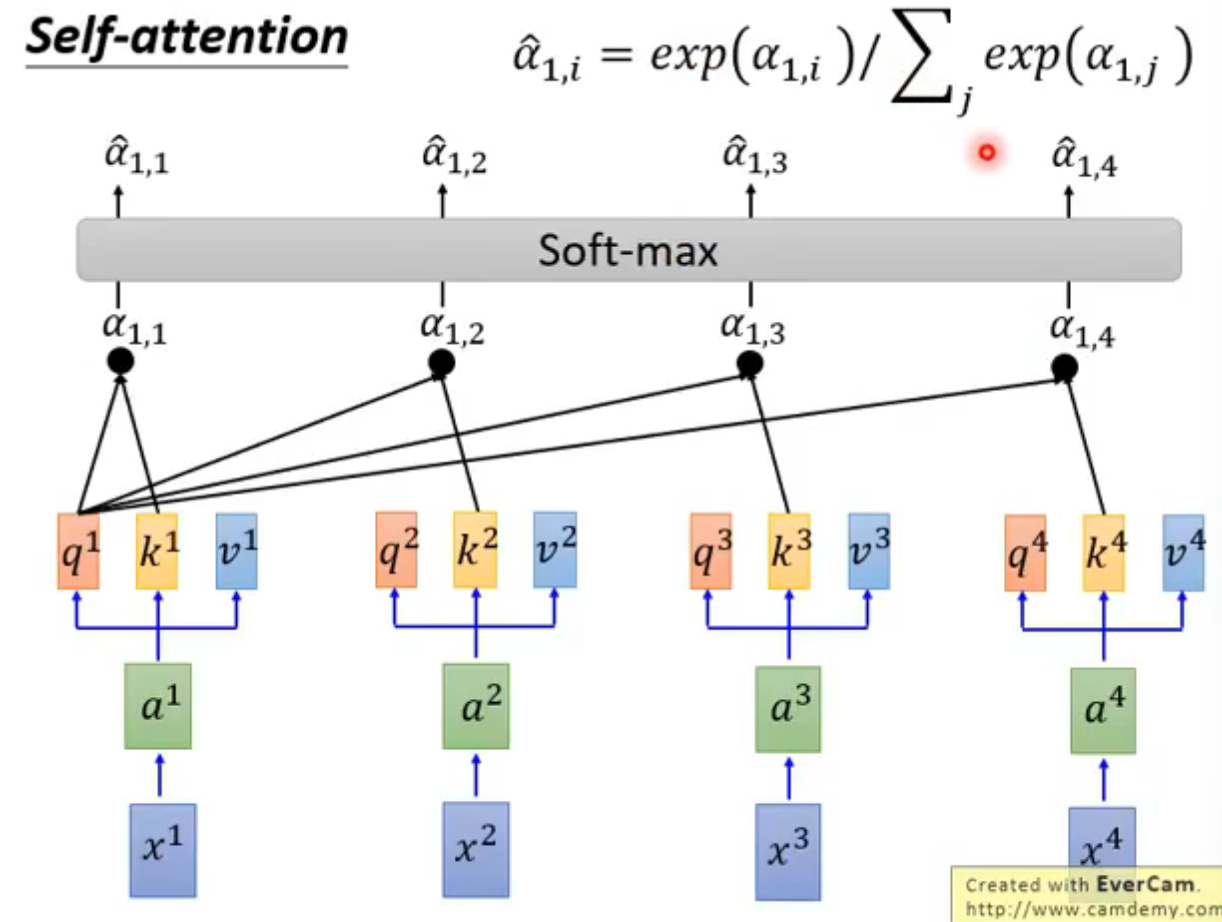
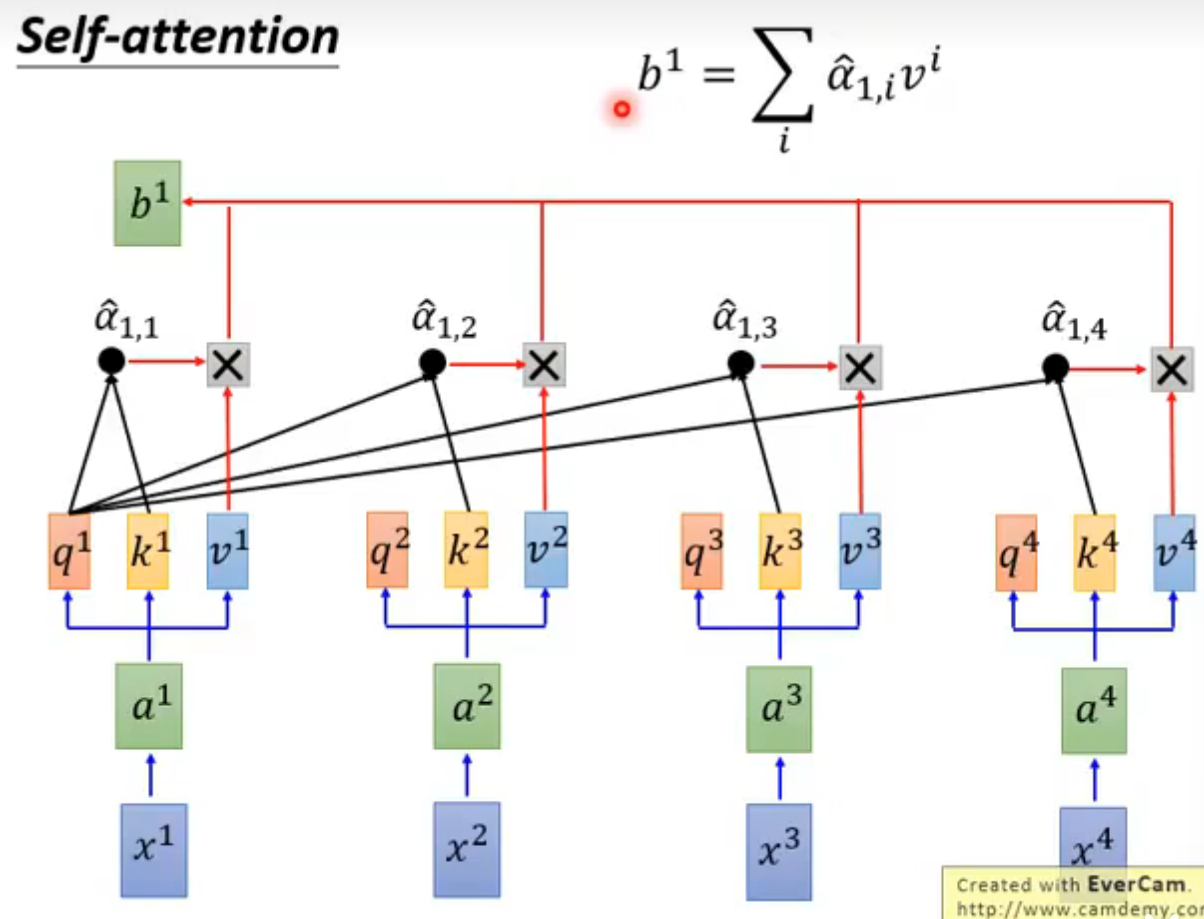
softmax后的α-hat与v相乘得到b
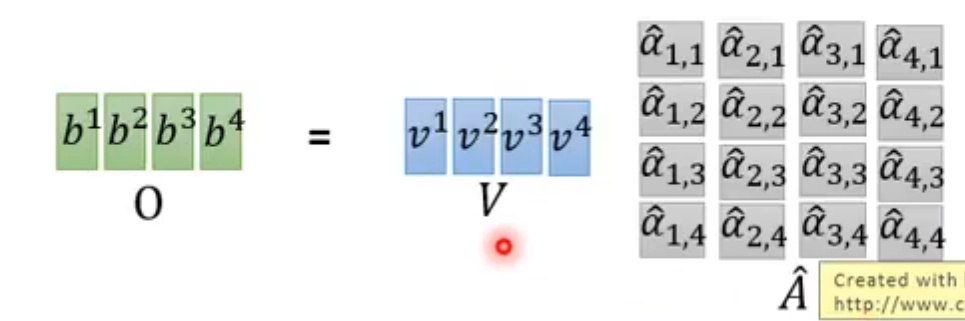
实际可以当做是矩阵运算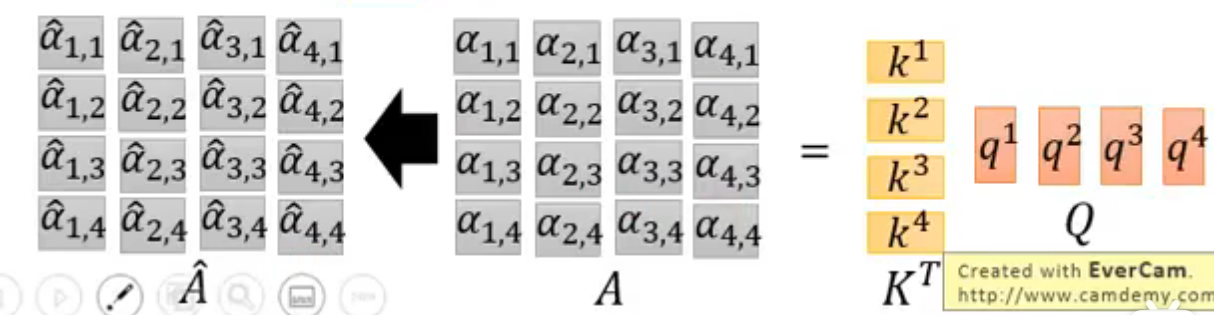
Multi-head Self-attention (2 heads as example)
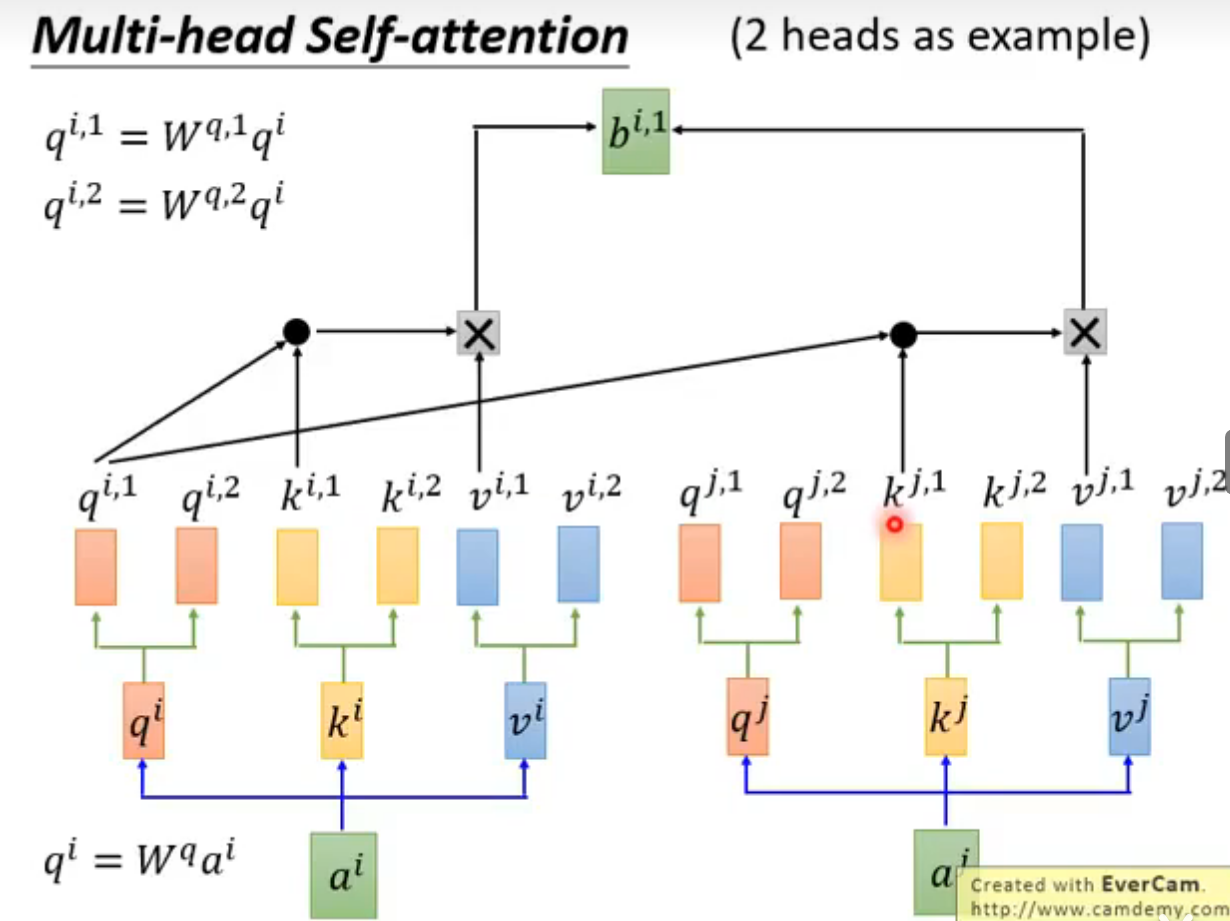
角标相同的做attention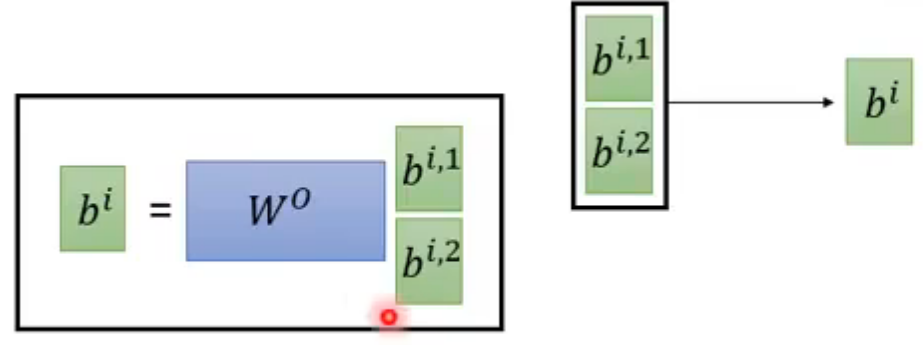
得到的bi,1和bi,2做一个transform得到bi
head的数目也可以作为一个可调参数
Positional Encoding
前面的self-attention和输入输出的位置无关,所以ai又加了一个ei向量标定位置(这个向量是人为设置的,不是学来的)
这里ei和ai直接采用相加,而没有采用拼接,是因为两者实际上在数学上可以被证明是等价的(见下图)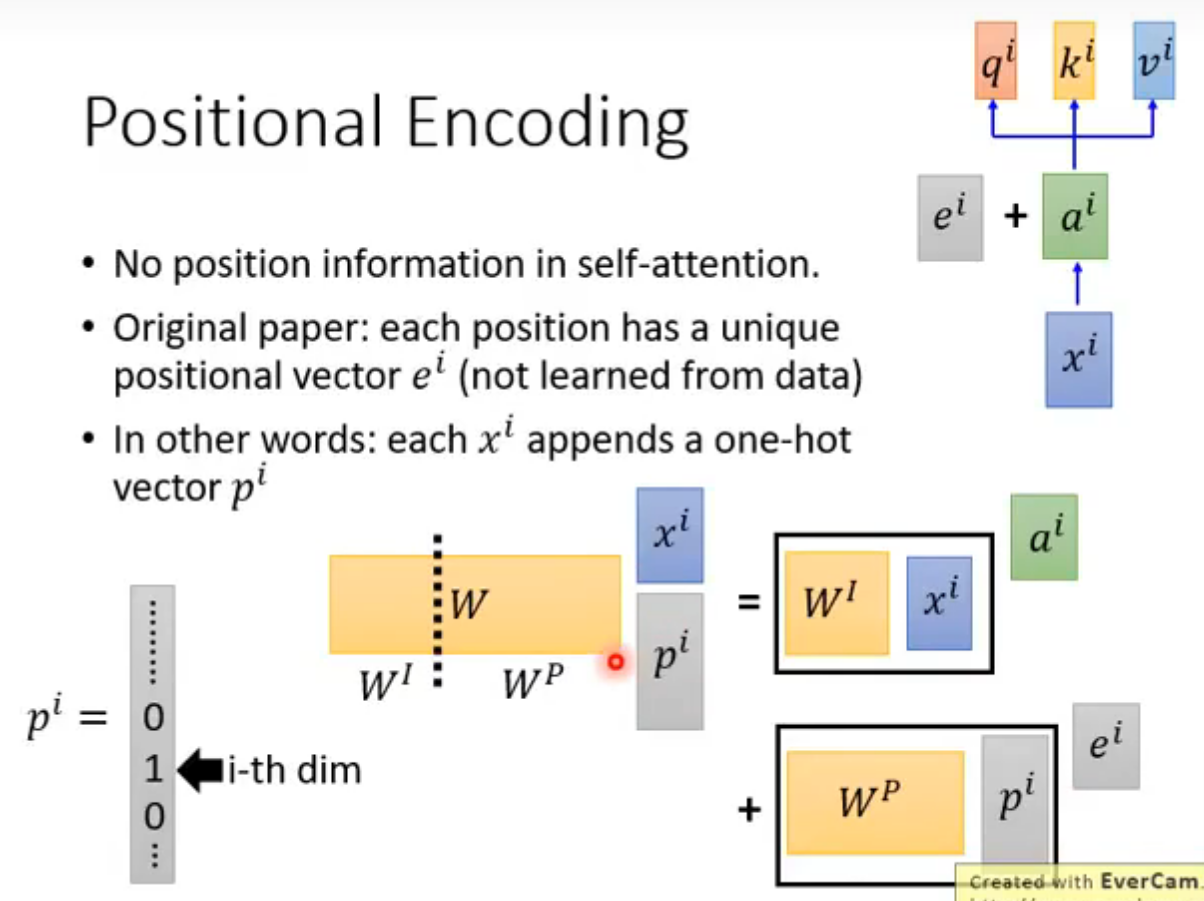
Seq2seq with Attention
encoder-decoder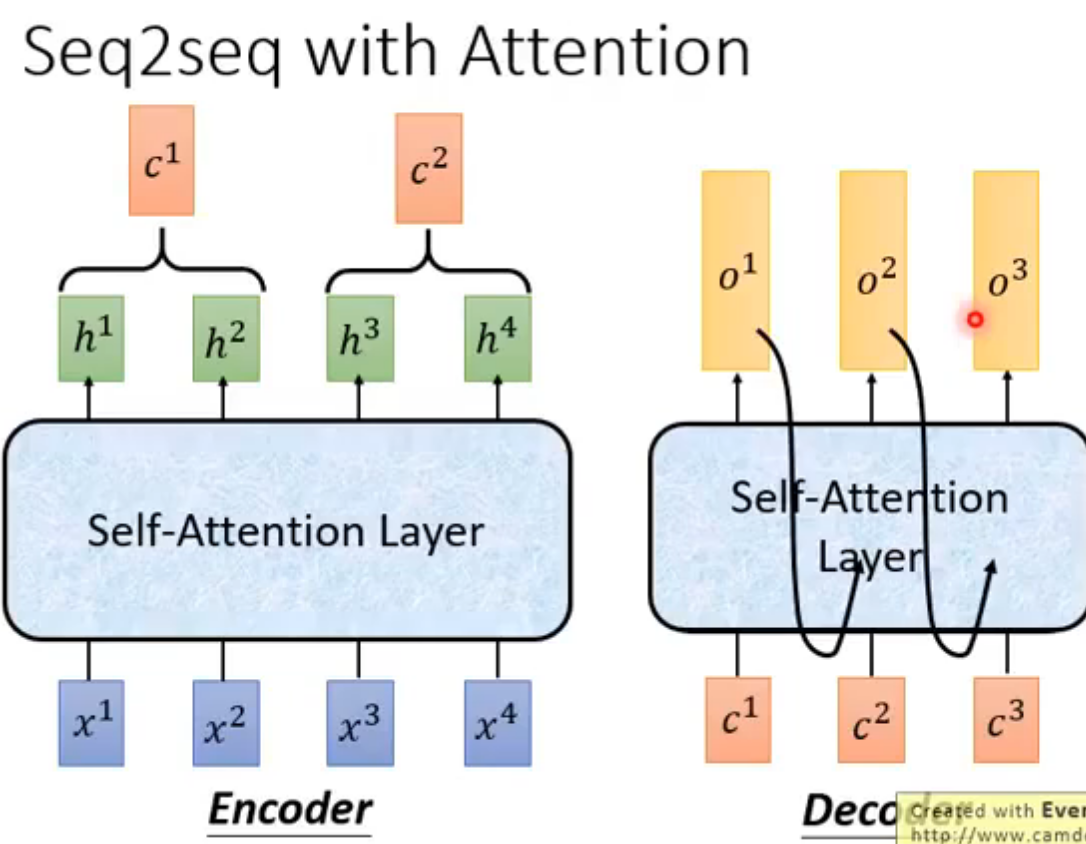
Universal Transformer
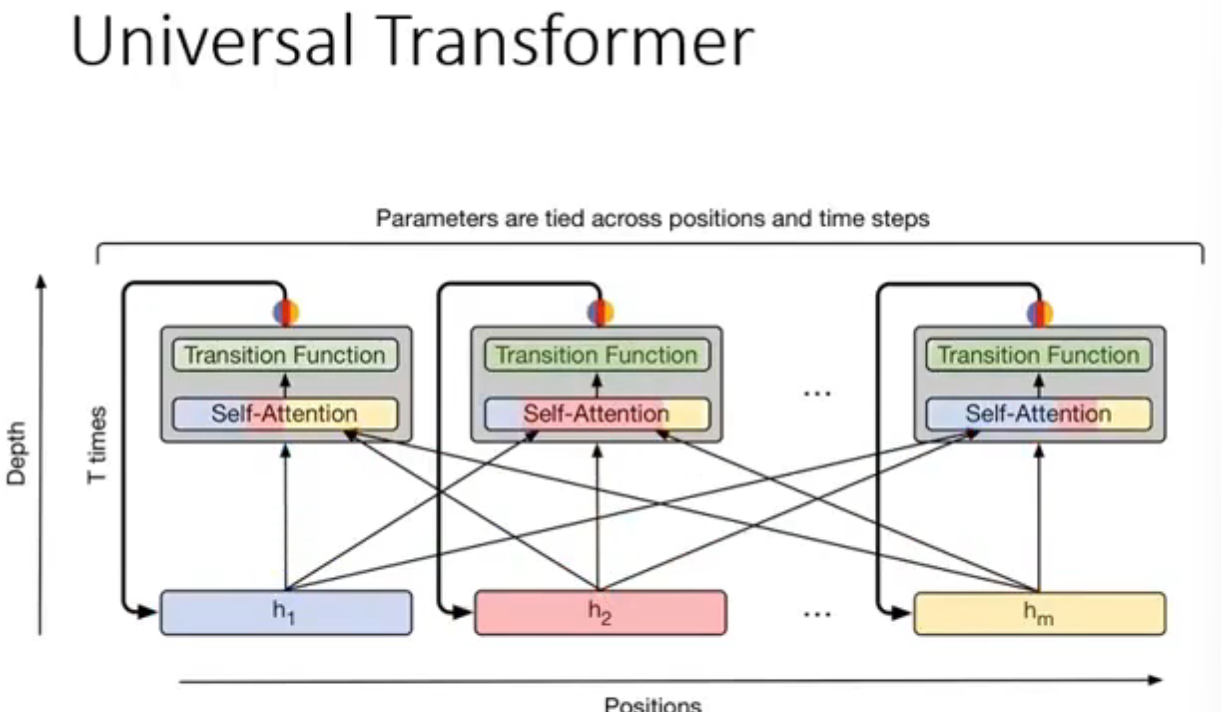
深度变成时间
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 星辰の博客!
评论
WalineTwikoo