
李宏毅机器学习笔记P51——attention
Attention
视频坐标24:00
Dynamic Conditional Generation
让Decode再每一个时间点的input都是不一样的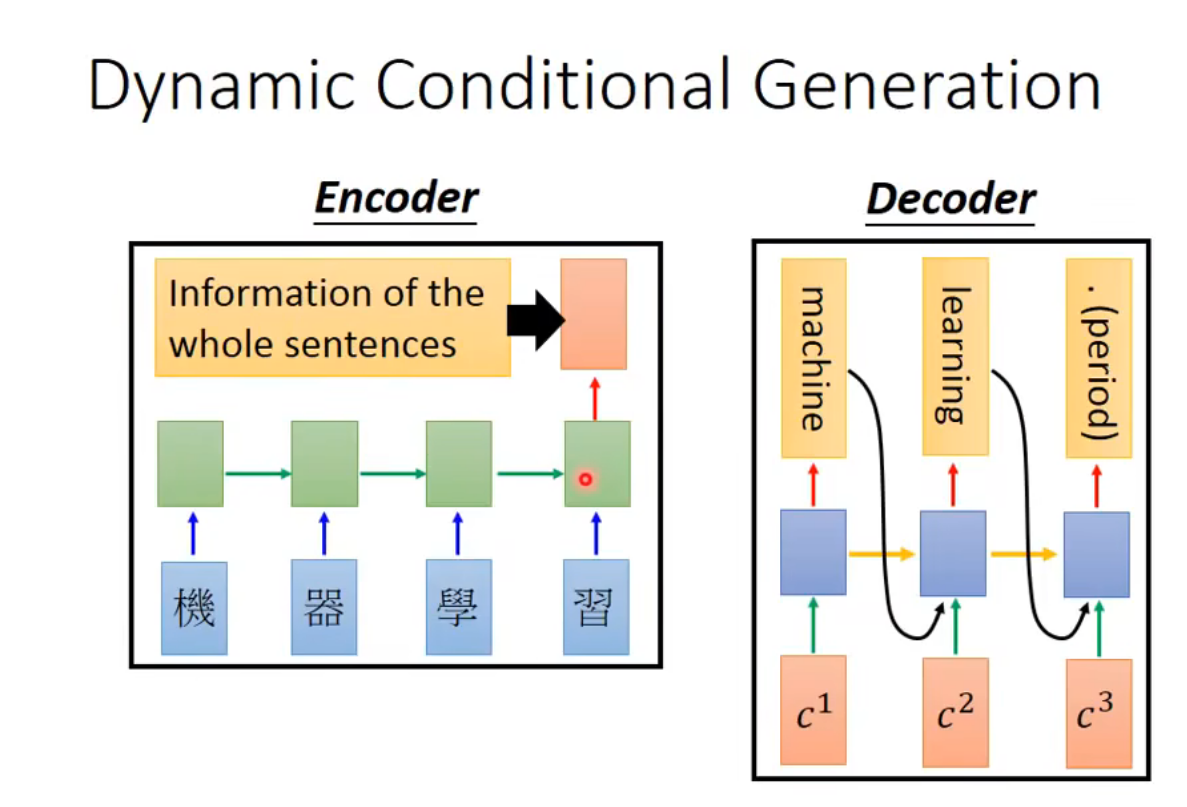
好处:
1.Encoder没法只用一个Vector来描述
2.Decoder考虑比较需要的Information
例子:
- Machine Translation
Attention-basd model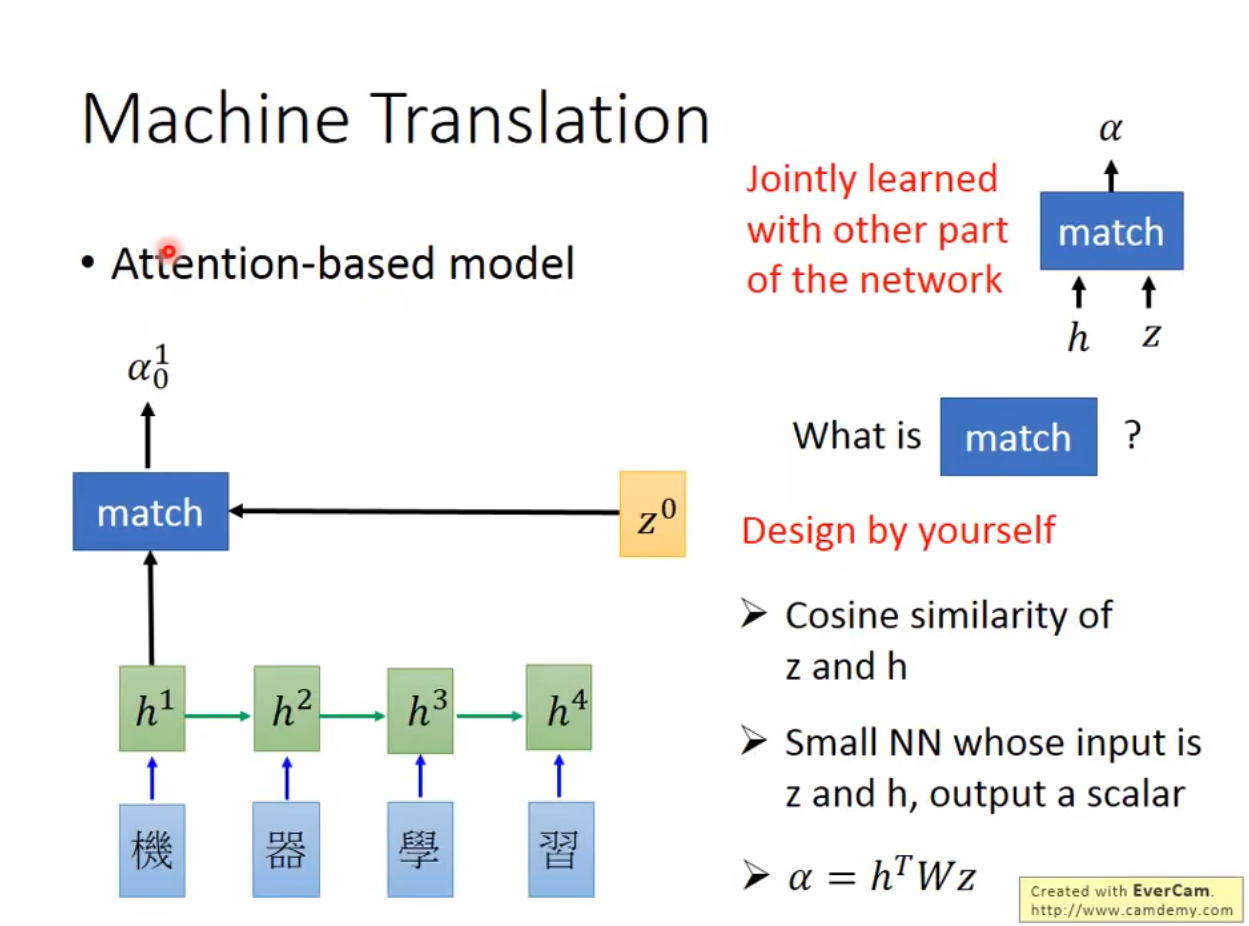
计算z0和h1有多match
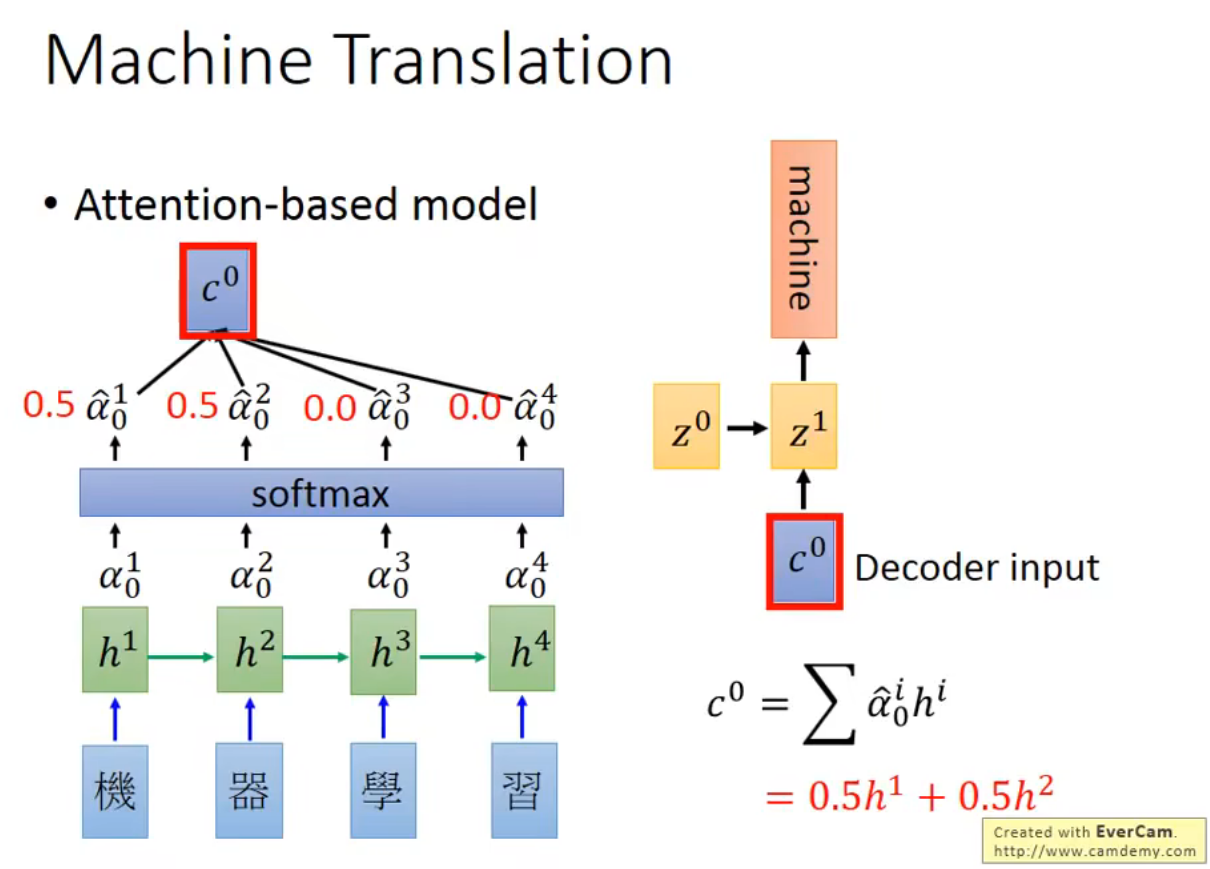
z1可以是c0在RNN里的输出,也可以是丢进隐藏层后的输出
然后继续把z1再算一次match,算softmax
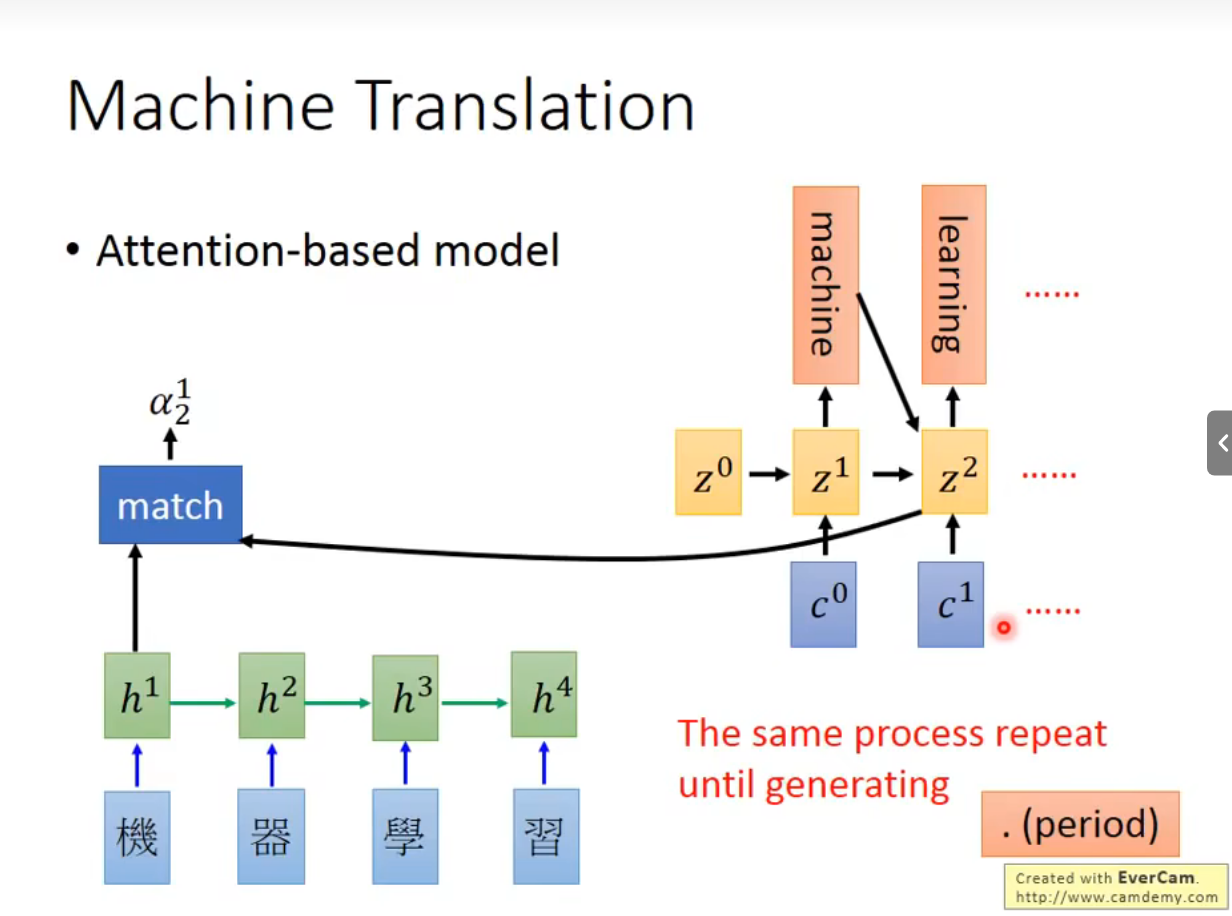
Speech Recognition
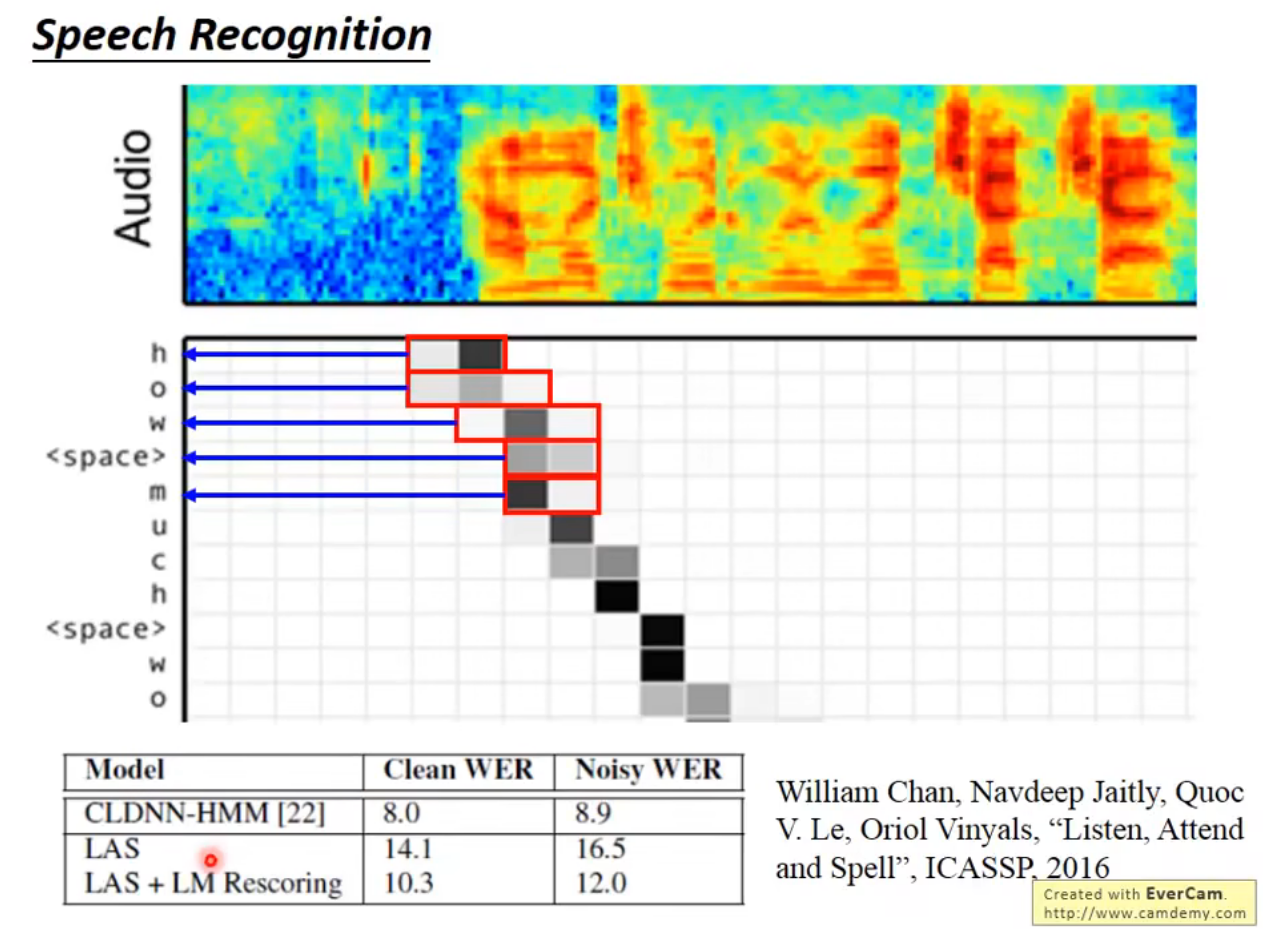
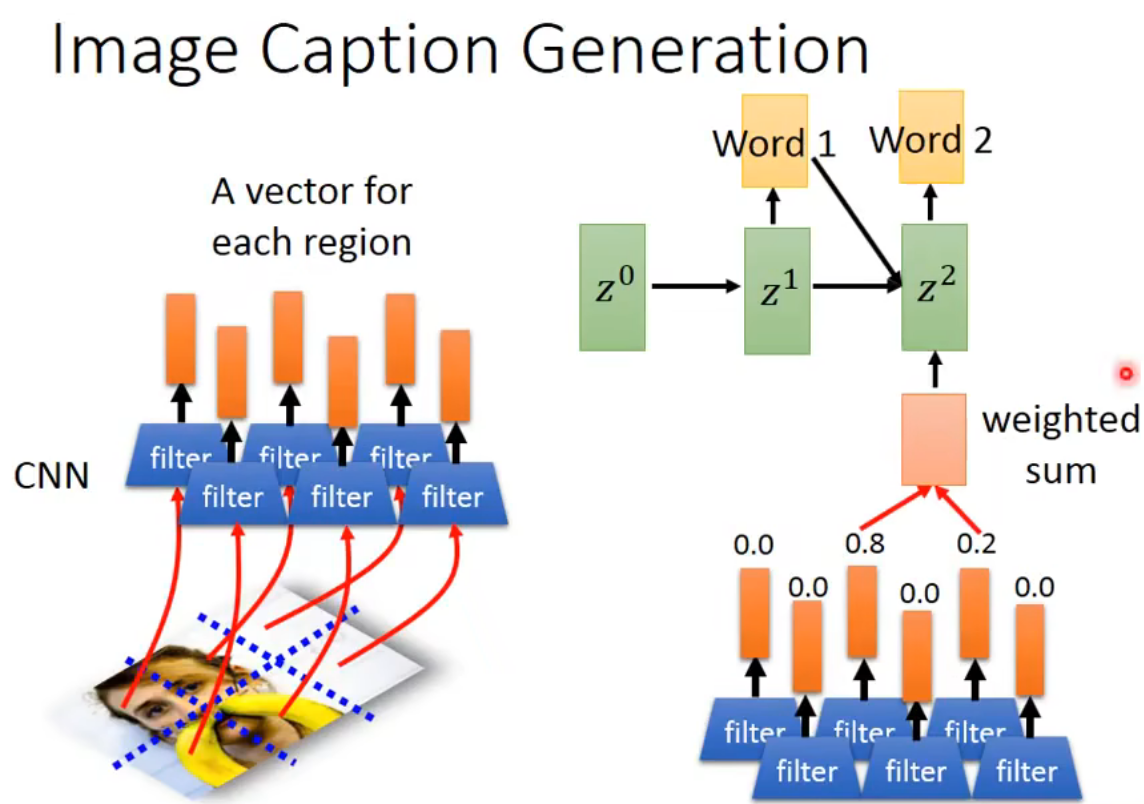
Image Caption Generation
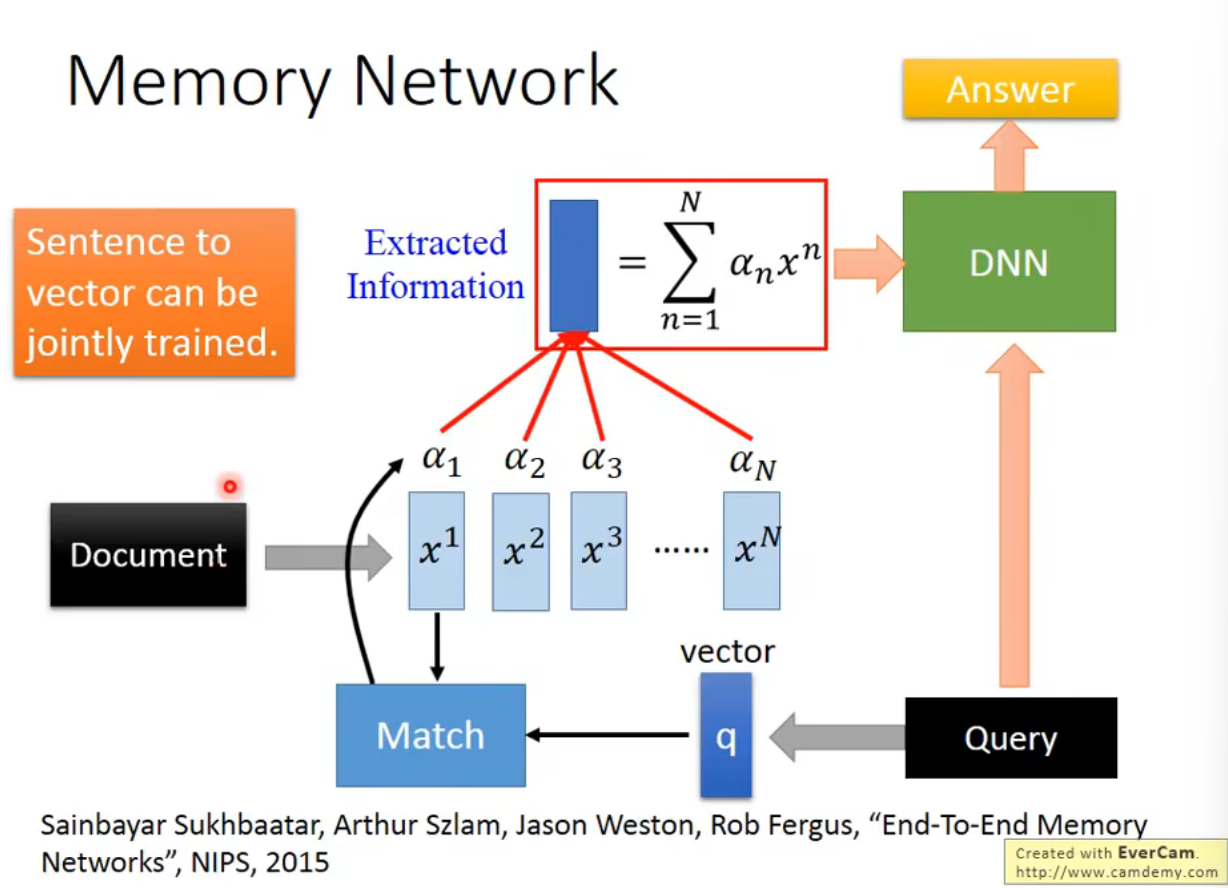
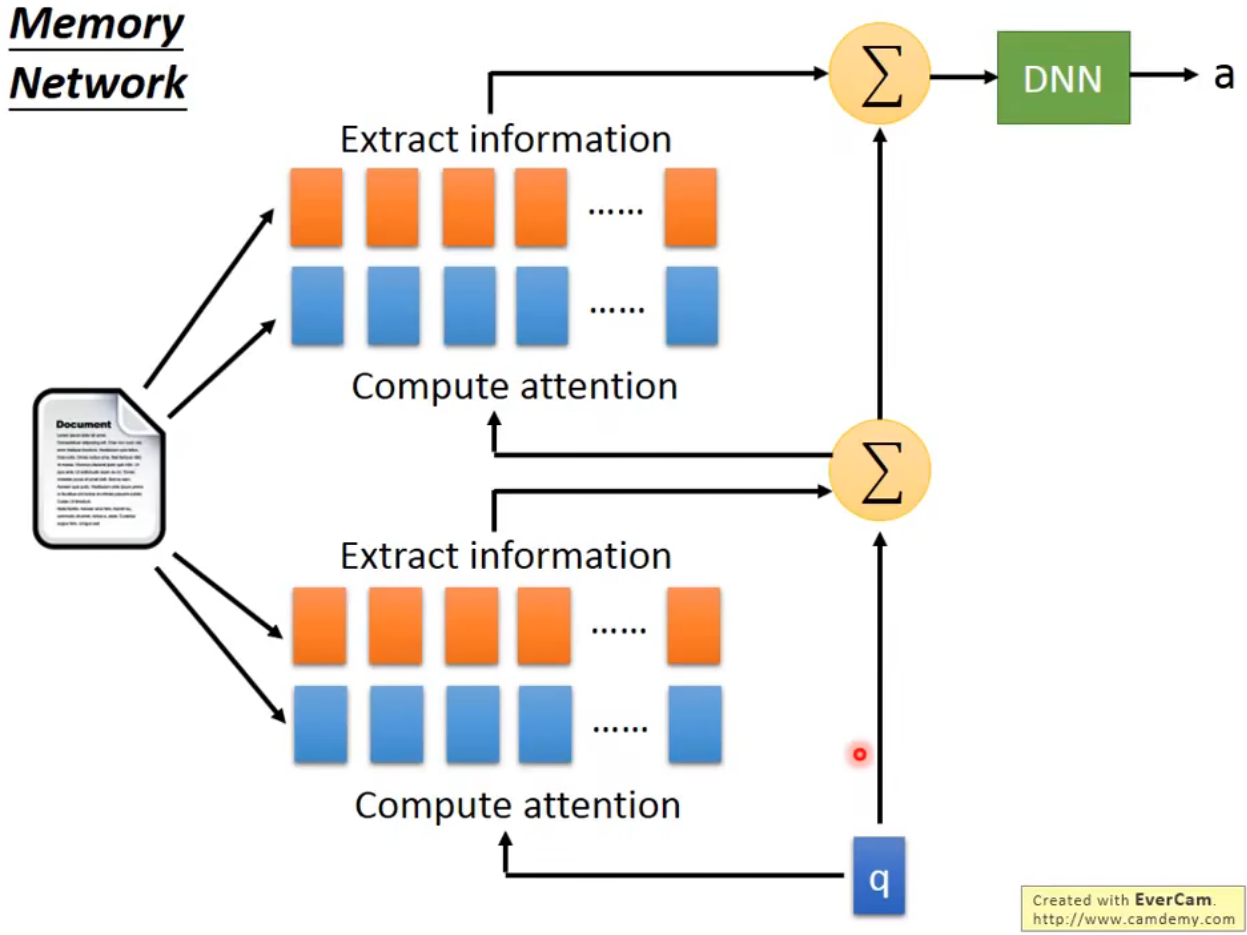
经过卷积层的输出当做RNN的输入Memory Network
更复杂的版本:抽取information和match的vector是不同的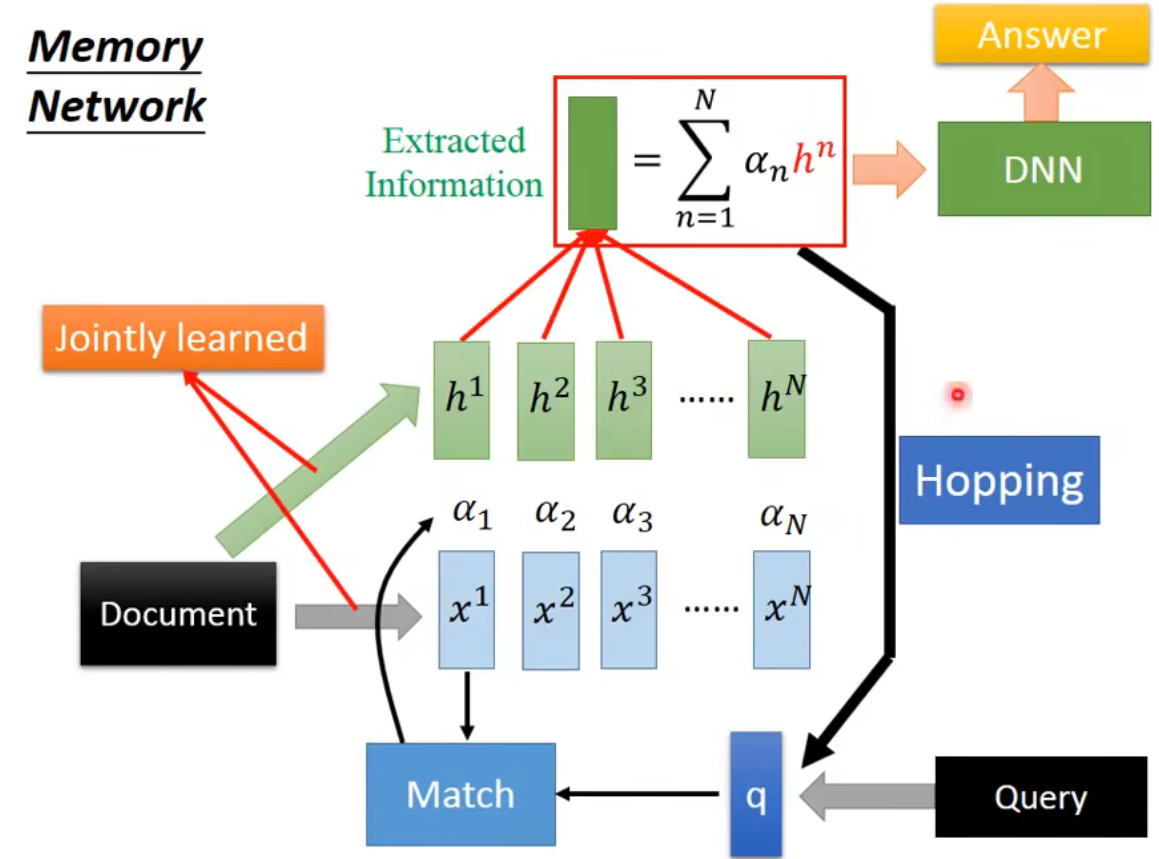
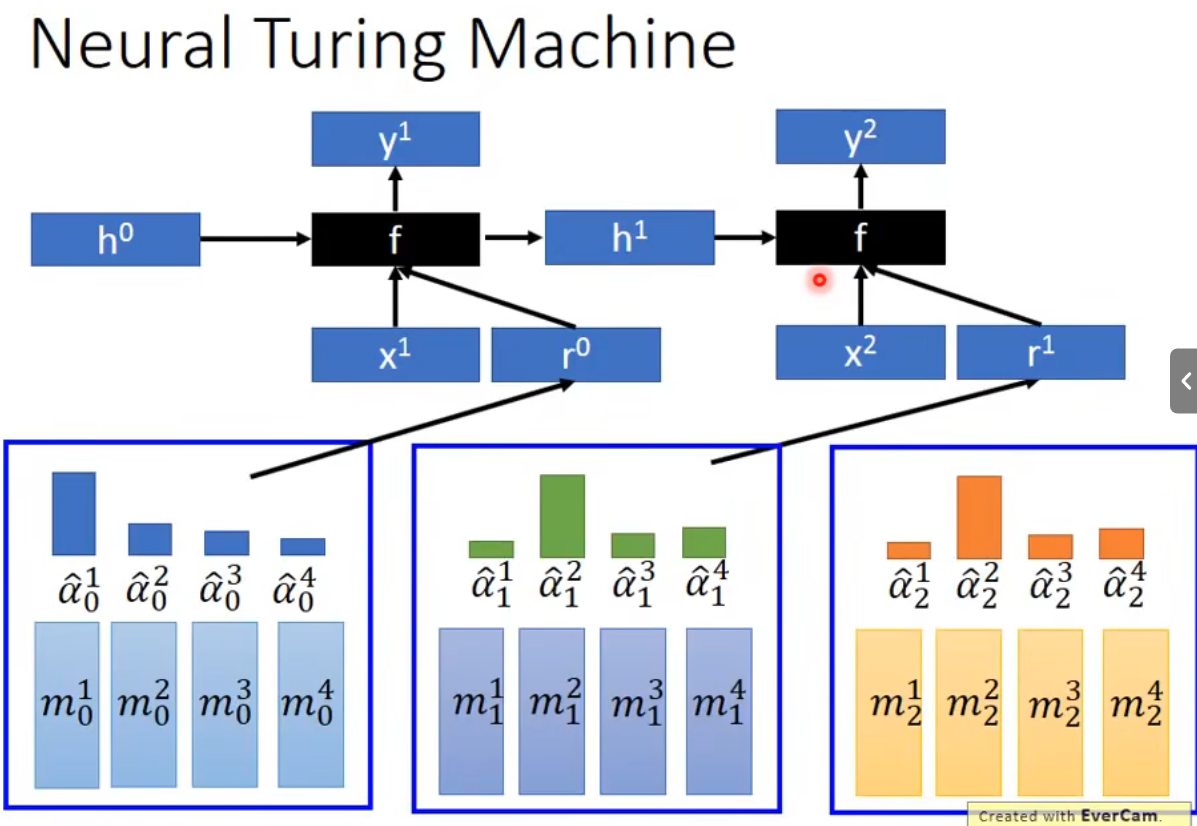
Neural Turing Machine
可以读memory的内容,也可以改memory的内容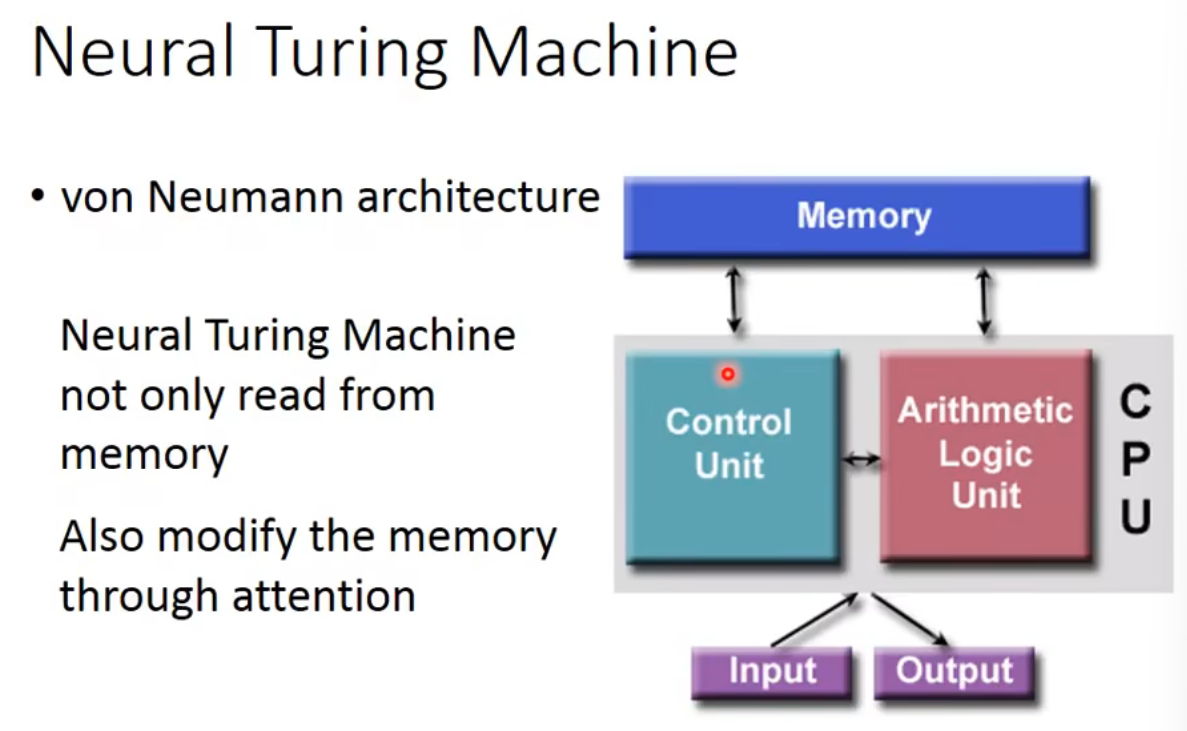
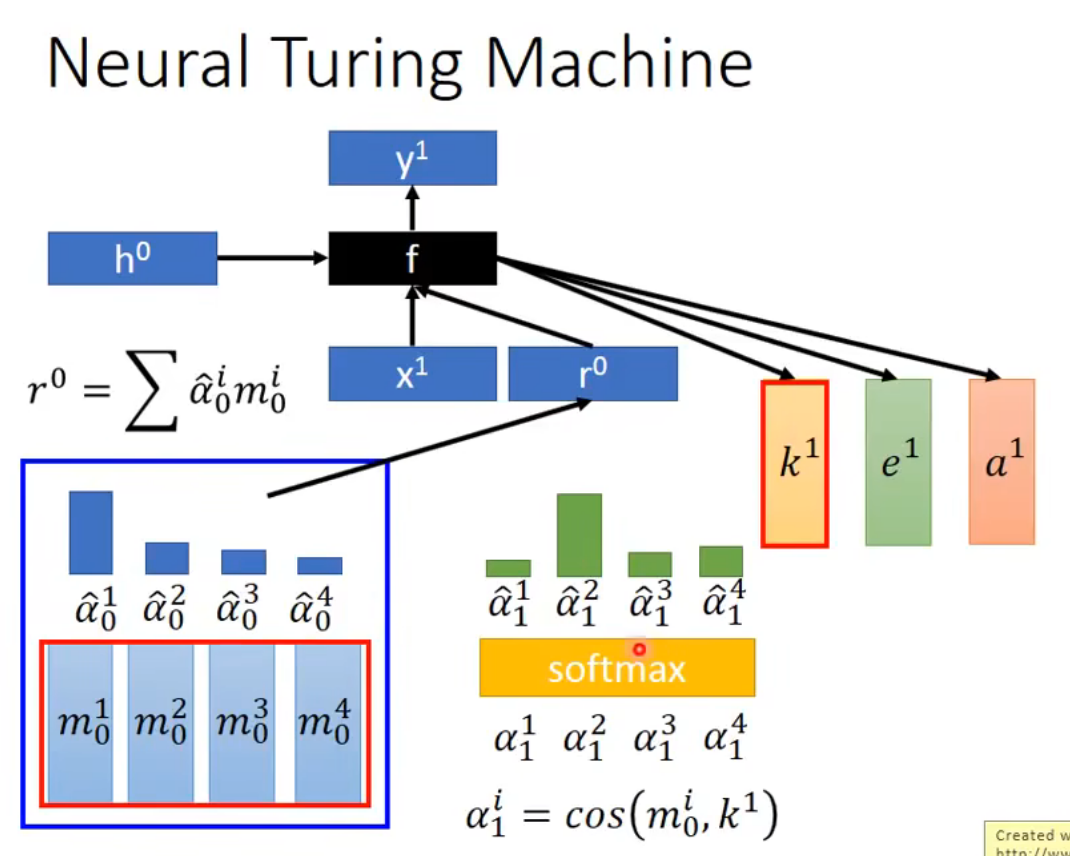
function的输出是三个vector:k,e,a
k的作用是产生attention
e的作用是去除旧的memory
a的作用是写入新的memory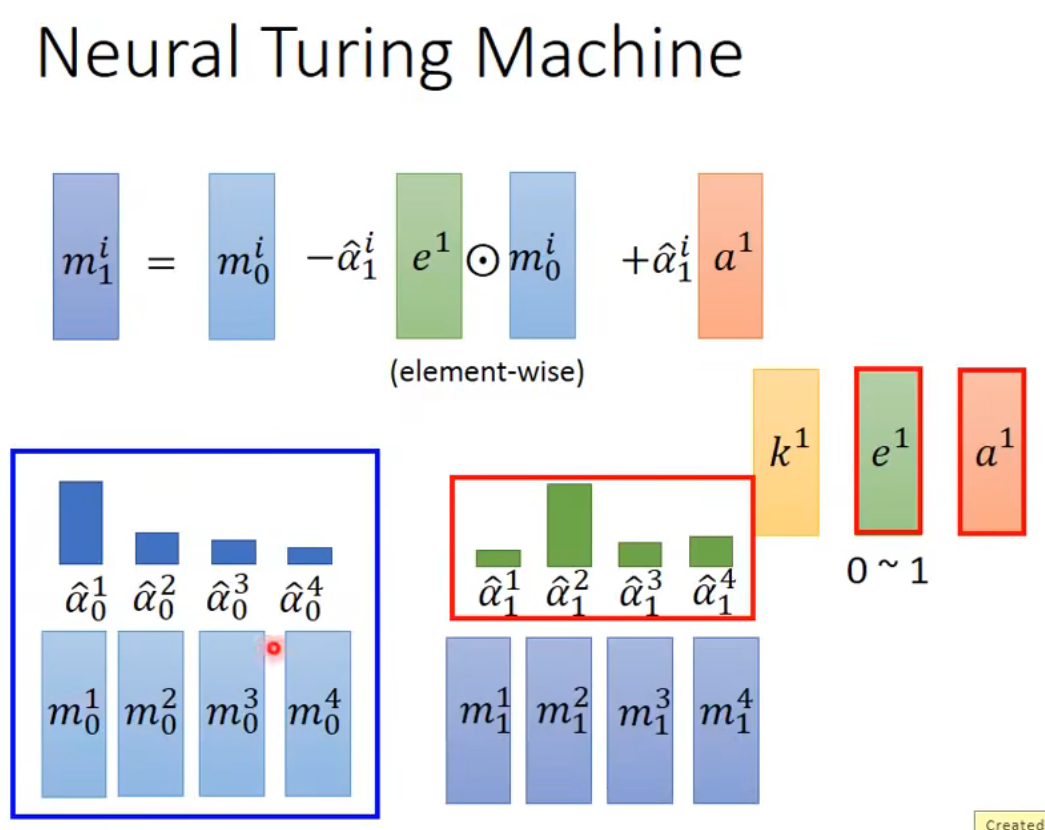
Tips for Generation
attention regularization
关注视频的每一帧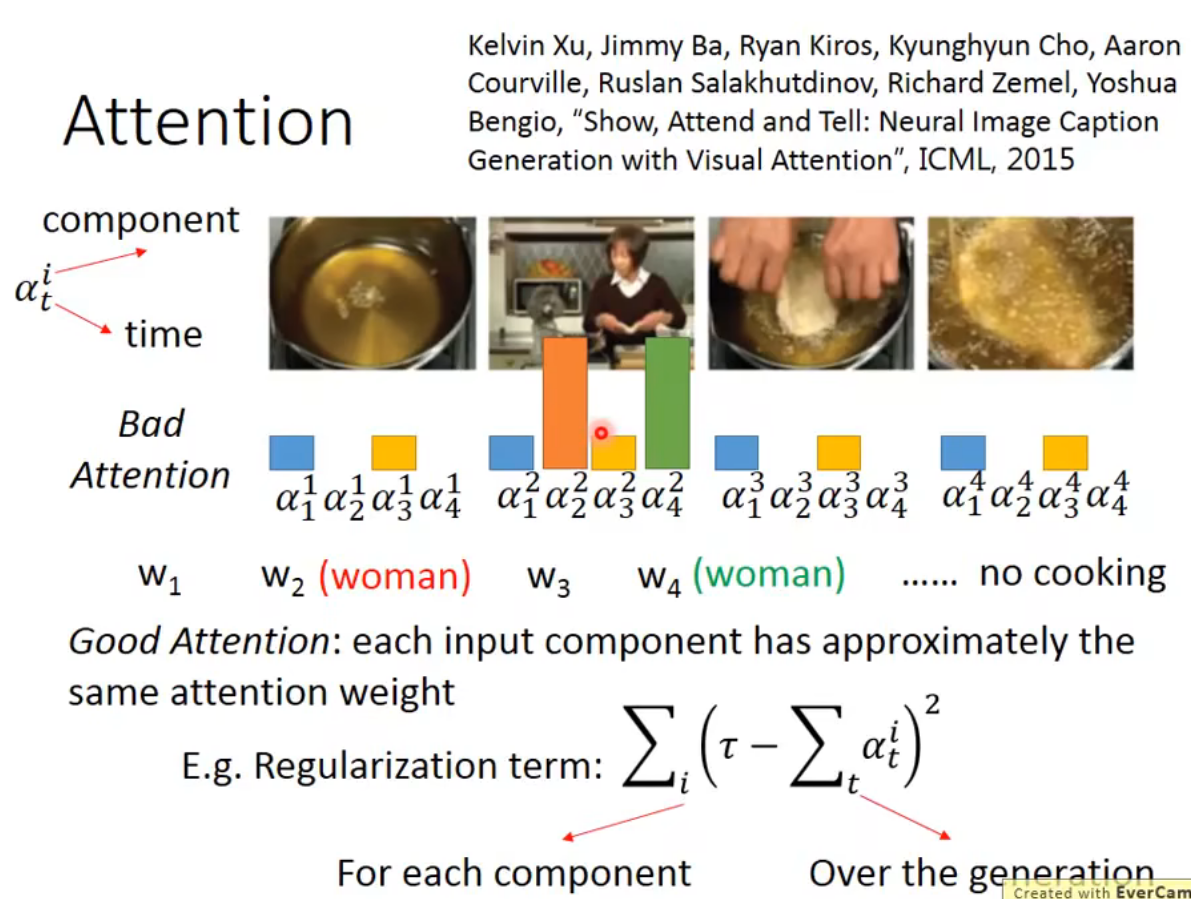
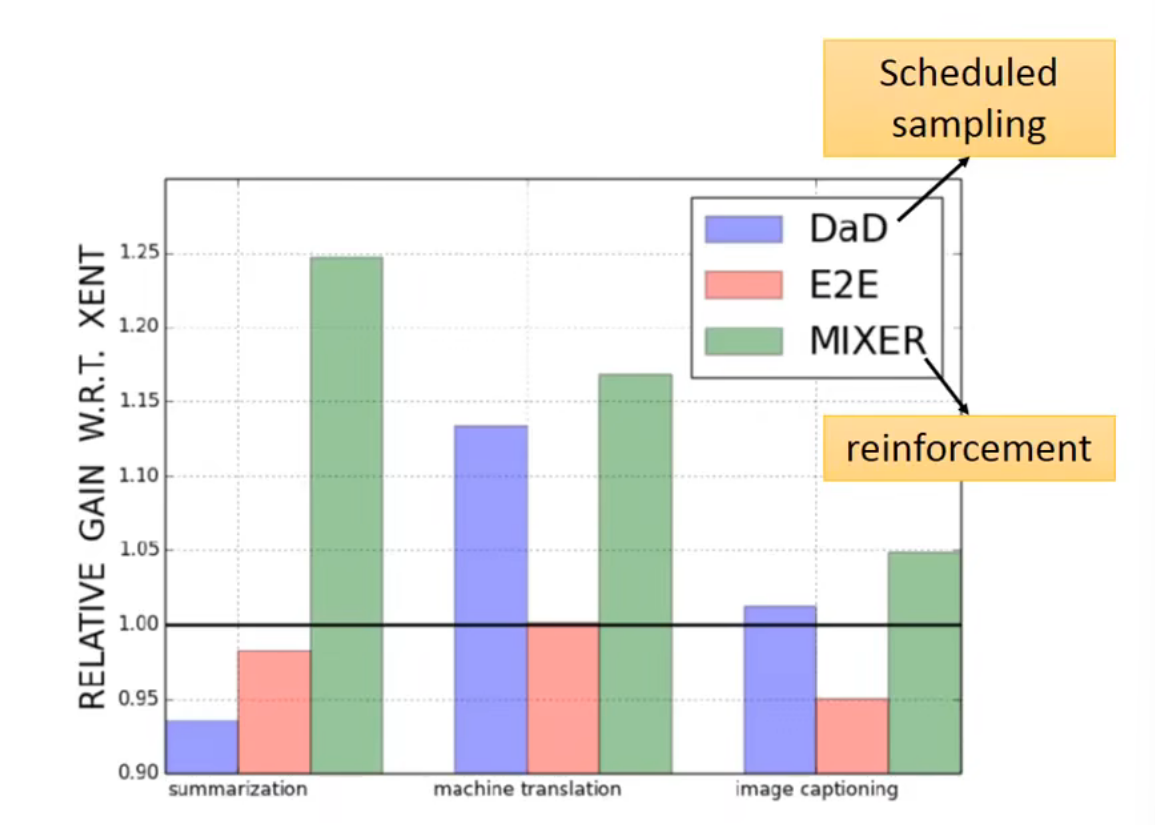
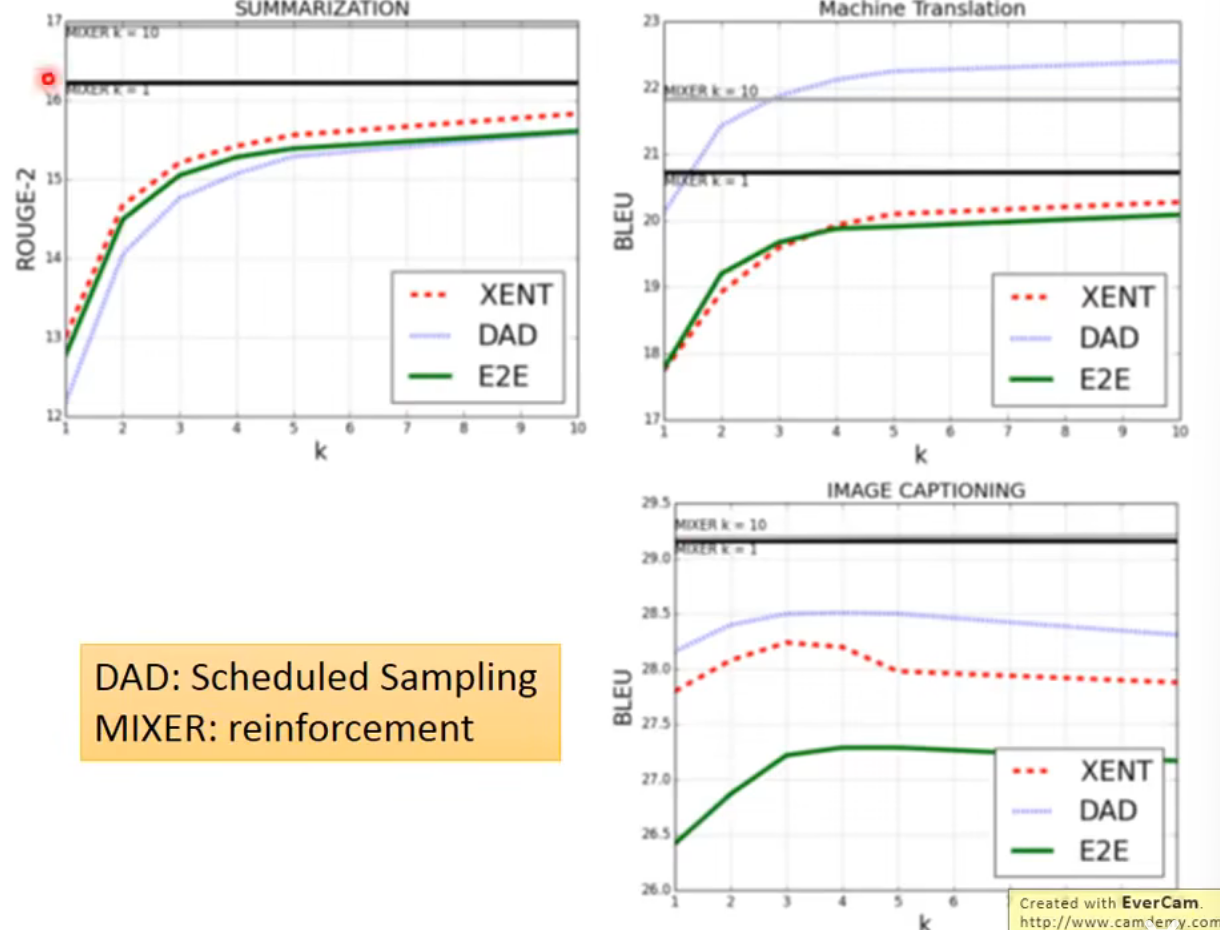
Scheduled Sampling
train的时候随机产生下一时间的input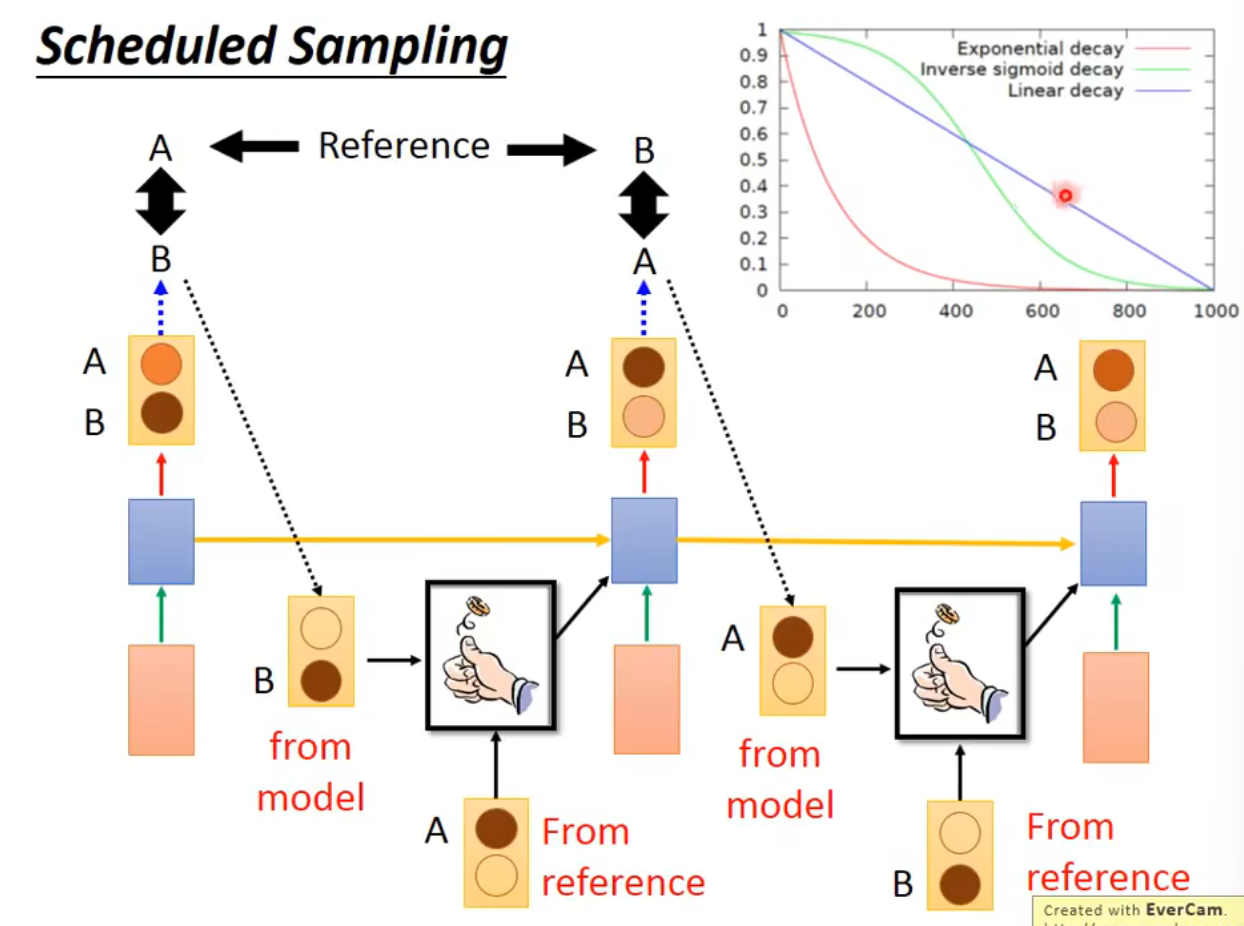
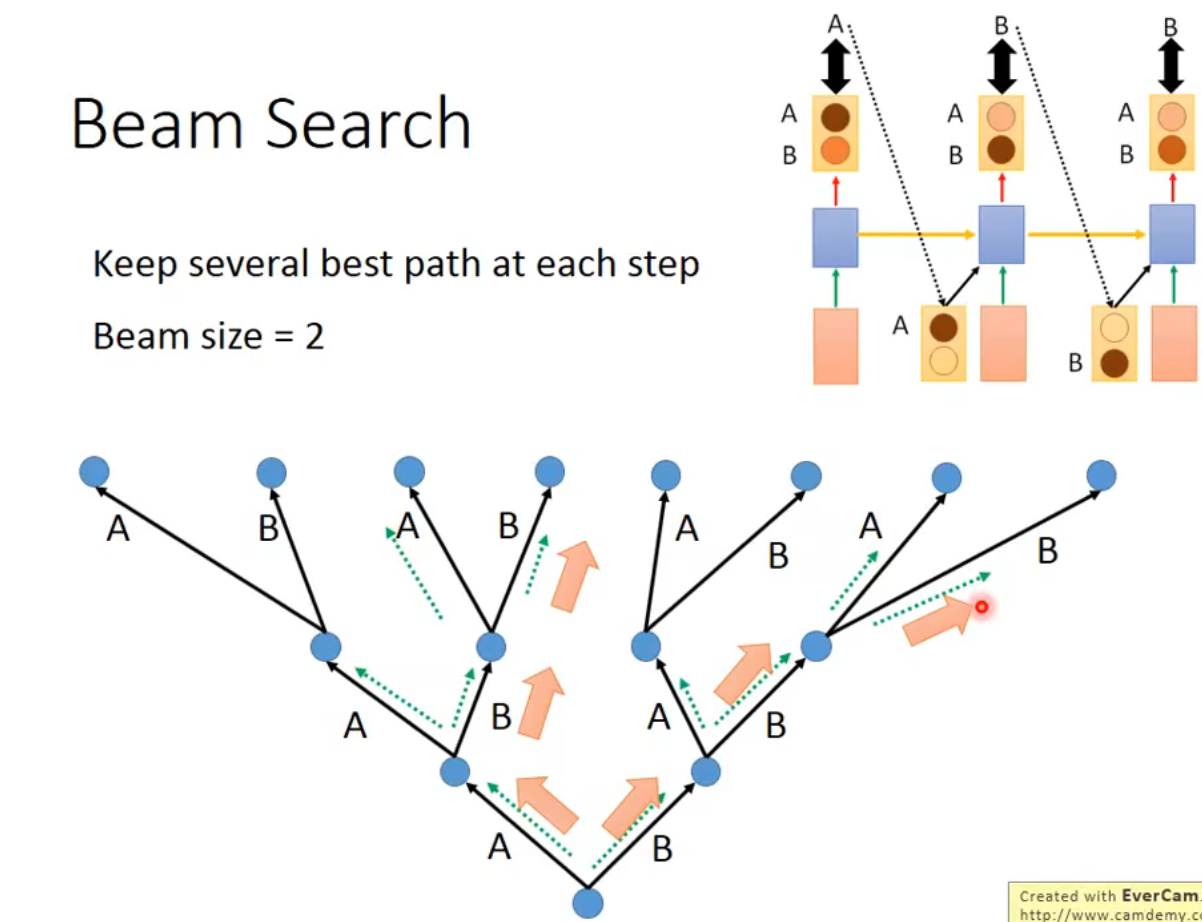
Beam Search
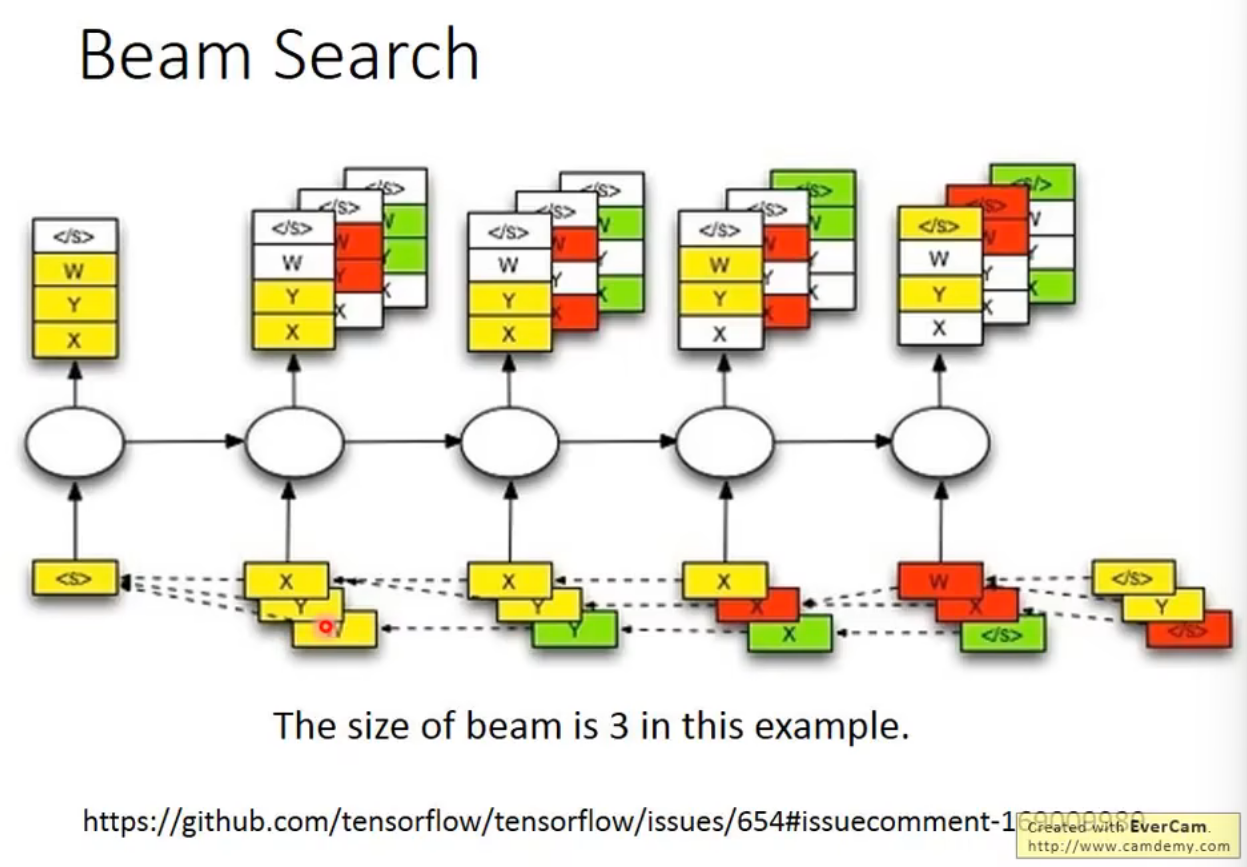
Object level v.s. Component level

如果采用交叉熵定义loss,那么从一个loss较小的错误的结果训练到正确的结果可能很困难,所以需要采用另一种定义loss的方法。但这种方法可能是不可微分的
- Reinforcement learning
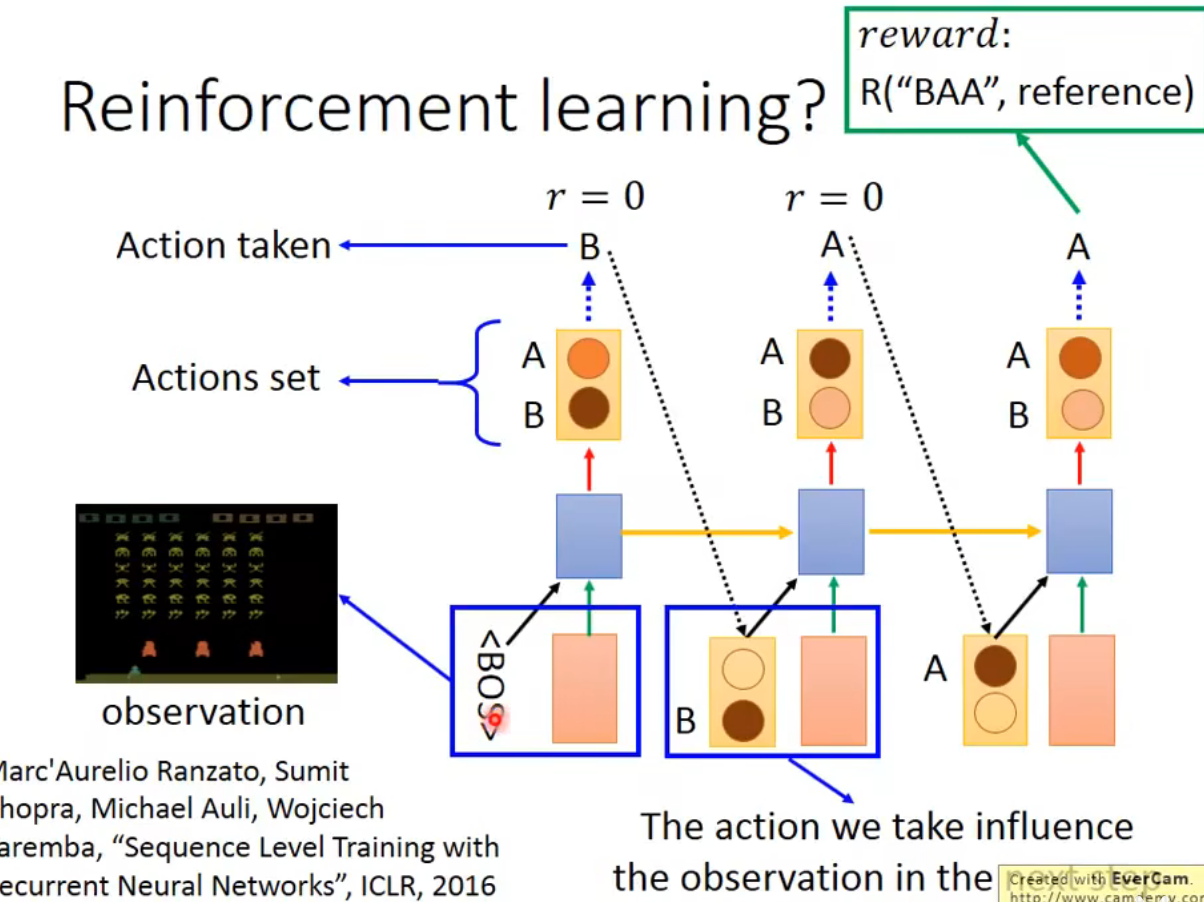
性能比较
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 星辰の博客!
评论
WalineTwikoo